python学习基础模块笔记整理(一)
3095人浏览 / 36人评论
pickle模块用法(用于将内存中的变量序列化至硬盘)
import pickle
a = "hello"
with open("file.pkl","wb") as f:
result = pickle.dump(a,f) #序列化a至文件file.pkl
with open("file.pkl","wb") as f:
result = pickle.load(f) #从file.pkl文件读取变量数据至内存
os 模块用法
import os
os.path.exists("test.txt") #判断文件是否存在
os.mkdir("img") #创建文件夹
os.path.join("img") #路径拼接
os.listdir("img") #查看路径下所有文件numpy模块用法
import numpy as np
np.empty([2,2]) #空矩阵
np.zeros((5)) #返回值都为0,长度为5的数组
np.ones((5)) #返回值都为1,长度为5的数组
np.asarray([[1,2],(3,4)]) #数组转为矩阵
np.random.randint(2, 5, size=(2, 2)) #生成值为2-5之间的2行2列随机数矩阵
np.random.randn(2, 2) #生成服从$N(0, 1)$的标准正态分布
np.arange(300) #返回0~299整数列表
np.arange(24).reshape(4,6) #将0~23的值转为4行6列矩阵
np.random.shuffle([0,1,2,3,4]) #将array中的值重新洗牌输出
m1 = np.arange(15).reshape(3,5)
m1.transpose(1,0) #m1进行列位置转换
m1.reshape(1,15) #将m1转为1行15列矩阵,等同于m1.reshape(1,15)
m1.reshape(-1,1) #将m1转为15行1列矩阵,等同于m1.reshape(15,1)
#矩阵切片
m1 = np.arange(27).reshape(3,3,3)
m1[1:2,:,:]
m1[1,:,:] #按固定索引切片适用于高纬,低维易导致降维
m1[:,:,1]
m1[:,:,None,1] #添加None可解决上面的降维问题
#矩阵运算
m1 = np.arange(15).reshape(3,5)
m2 = np.arange(15).reshape(5,3)
m3 = np.arange(3).reshape(1,3)
result = m1 @ m2 #矩阵乘法,要求m1行等于m2列
#广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
"""
广播的原则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
- 输出数组的形状是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
需要满足:
- 数组拥有相同形状。
- 当前维度的值相等。
- 当前维度的值有一个是 1。
"""
result = m1 + m2 #矩阵加法,m3会自动广播cv2,plt模块用法
import matplotlib.pyplot as plt
import cv2
"""
用opencv(即cv2)读取图片,是以BGR的形式来读取的。我们用cv2的imshow()函数显示图片发现跟我们打开图片的样子一样,是因为cv2的imshow()又把BGR转回RGB再显示。但cv2确实是以BGR形式读取图片的,而plt则是以RGB形式。
"""
img = cv2.imread("cat.jpg") #读取图片为像素点矩阵
img = plt.imread(img_name)
img_h,img_w,img_c = img.shape #矩阵大小
img[...,::-1] #BGR转回RGB
cv2.imwrite("img.jpg",img) #将矩阵写为图片文件
#图片展示
plt.imshow(img)
plt.show()re模块用法
import re
#将data日期格式转为年月日格式
data = "2021-08-31 10:13:12"
p1 = re.compile(r"(\d{3,})-(\d{2})-(\d{2}) (\d{2}):(\d{2}):(\d{2})")
p1.sub(r"\1年\2月\3日 \4时\5分\6秒",data)
#将文本中的特殊字符去除
p2 = re.compile(r"[\\/:\"'|\s<>*?,。!?,]")
p2.sub("",data)
requests,xpath模块用法
import requests
from lxml import etree
html = requests.get("url",headers = "headers",data = "data").text
requests.post("url",data = "data").json() #请求参数格式为form_data
requests.post("url",json = "json").json() #请求参数格式为json
data = etree.HTML(html)
data.xpath("/html/body/div[4]/div[1]/div[3]/div/div/div[1]/p/text()") #绝对路径
data.xpath("/html/body/div[4]/div[1]/div[3]/div/div/div[1]/a/img/@data-src")
data.xpath("//*[@id="page_content"]/div[2]/div[1]/div[2]/div[1]/div[3]/p/text()") #相对路径jieba模块用法
import jieba
from jieba.analyse import tfidf
key_words = sorted(tfidf(question, withWeight=True),key=lambda i:i[1],reverse=True)
key_words_cha = set(jieba.lcut(question)) - set([j[0] for j in key_words])
key_words.extend([(c,1)for c in key_words_cha])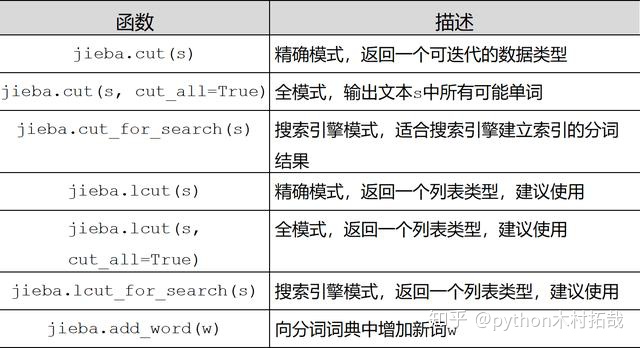


全部评论